

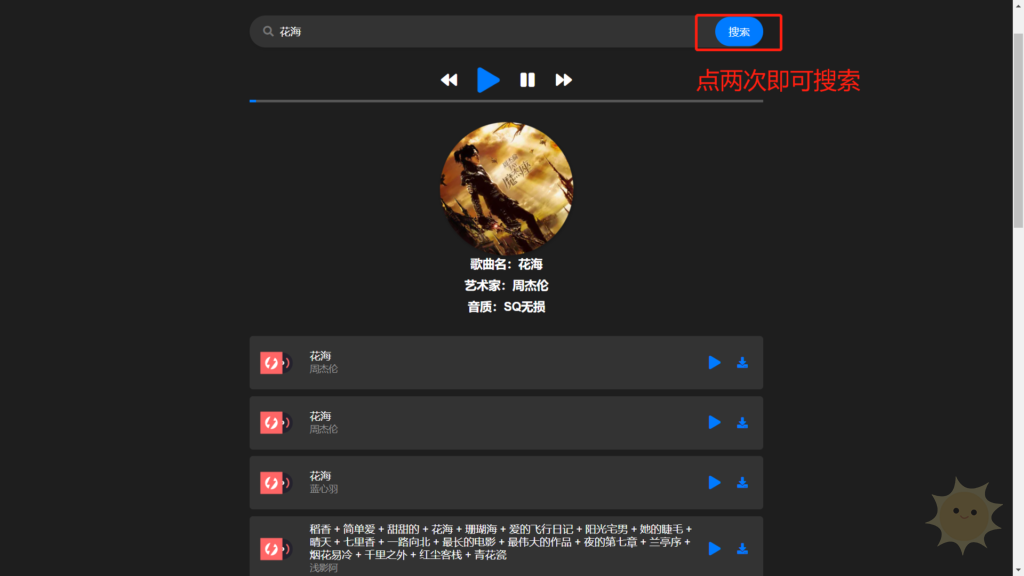
大家好呀,今天山海的音乐网站开发完了,可以在山海的网站上听高音质的音乐了,网站在这里https://muisc.nmsb.vip/。山海为了防爬虫,在搜索的时候加了一个需要点击两次搜索才能搜索到音乐的功能,作为一个爬虫爱好者,我想尝试他的网站反爬功能怎么样,接下来小编带你一起爬山海的音乐网站吧(注:山海音乐网站属于这个网站的站长名下)
一、抓包
首先抓到数据,然后我们才能分析它是怎么样请求的
打开https://muisc.nmsb.vip/,按键盘快捷键‘f12’或者‘右键’检查打开网页抓包功能

之后你就会来到这个界面。然后你会发现它自动断点了,我们去看‘网络’那里,刷新一下发现没有什么数据,有也不是我们想要的


怎么解决这个问题呢?我们只需要把断点给停掉就行。如下图,在‘源代码’界面,点击图示图标,等图标变蓝后就是停用断点了

这个时候我们再刷新就发现没有停在这个网页上了

这个时候我们再搜索一首歌并播放,来到‘网络’面板,我们就看到有好多数据了


因为山海设计该网站的时候就是设计反爬虫的,所以我们不用在‘全部’那个数据面板找,而是在 fetch/xhr 找,我们在‘响应’那里看到好多关于‘意外’的信息,说明这个就是我们要找的‘搜索’接口。我们复制下来https://www.shserve.cn/api/music/?msg=%E6%84%8F%E5%A4%96,可以发现这是一个接口链接(一般带有api字眼的就是接口链接),它携带msg参数,但是这个参数是什么意思呢,我们来解析看看

可以看到它是‘意外’的url编码,那就好办了。那‘搜索’这一功能就有思路了。

我们在看看其它数据,这条数据有一个疑似音乐链接的url,我们用idm下载看看

可以看到是这条链接就是这个音乐的链接,它的请求链接是这个https://www.shserve.cn/api/music/?msg=%E6%84%8F%E5%A4%96&n=1。在这里我们可以看到这个链接跟上面那个链接差不多一样,只是多了一个n参数,那我们在发送获取歌曲链接请求的时候再添加n参数上去就可以了

至此抓包环节结束,我们开始敲代码吧
二、撸代码
1. 导入requests模块;urllib的url编码模块
import requests
from urllib.parse import quote#quote是url编码,unquote是url解码2. 创建一个类,把这些函数包装起来
class ShanHai():
# 实例化self,这样子下面的函数不用每次都引用一个变量
def __init__(self,songName):
# 编码搜索的名字
self.name = quote(songName)
# 实例化接口链接
self.url = 'https://www.shserve.cn/api/music/?msg='
# 实例化请求头
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}
if __name__ == '__main__':
# 要求输入搜索内容
n = input('您想要搜索什么歌或者歌手:')
# 引用上面class ShanHai()类
ShanHai(n)
3. 创建一个搜索、下载音乐函数
def Search(self):
# requests.session()是携带实时信息,这样就不用获取到相应cookie,用的网站需要cookie才能进,我们用requests.session()后就不需要获取cookie了,它会携带进去了
session = requests.session()
"""
# 这个函数要放到上方的类里面,self.url、self.name是上方类里的变量
data = session.get(url = f'{self.url}{self.name}',headers = self.headers).text
# 打印这些搜索到的信息,在抓包时说过,在这里打印时方便我们发送序号下载我们想听的歌
print(data)
"""
# 以下代码可以更好地帮你更好地找到你喜欢的歌曲所在在位置
data = session.get(url = f'{self.url}{self.name}',headers = self.headers).json()
list = data['list']
for iter,li in enumerate(list):
print(iter+1,li)
# 以下代码是发送请求后所返回的对应的歌曲名称,可以自己美化一些
num = input('请输入您喜欢听的歌曲所对应的序号:')
song_data = session.get(url=f'{self.url}{self.song}&n={num}')
song_url = song_data.json()['url']
song_content = session.get(song_url).content
# 这里我用你搜索的名称做文件名,可以更改
with open(f'./{n}.mp3',mode='ab') as so:
so.write(song_content)4. 完整代码
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
@File Name : 爬山海音乐.py
@Description :
@Author : 27822
@date : 2023/5/21
@Tool : PyCharm
personal_information:
ShanHai: https://www.shserve.cn/author/400
-------------------------------------------------
Change Activity:
2023/5/21:
-------------------------------------------------
"""
__author__ = 'ShanHai_魔法师'
import requests
from urllib.parse import quote # quote是url编码,unquote是url解码
class ShanHai():
# 实例化self,这样子下面的函数不用每次都引用一个变量
def __init__(self, songName):
self.name = quote(songName)
# 编码搜索的名字
self.url = 'https://www.shserve.cn/api/music/?msg=' # 实例化接口链接
# 实例化请求头
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}
def Search(self):
# requests.session()是携带实时信息,这样就不用获取到相应cookie,用的网站需要cookie才能进,我们用requests.session()后就不需要获取cookie了,它会携带进去了
session = requests.session()
"""
# 这个函数要放到上方的类里面,self.url、self.name是上方类里的变量
data = session.get(url = f'{self.url}{self.name}',headers = self.headers).text
# 打印这些搜索到的信息,在抓包时说过,在这里打印时方便我们发送序号下载我们想听的歌
print(data)
"""
# 以下代码可以更好地帮你更好地找到你喜欢的歌曲所在在位置
data = session.get(url=f'{self.url}{self.name}', headers=self.headers).json()
list = data['list']
for iter, li in enumerate(list):
print(iter + 1, li)
# 以下代码是发送请求后所返回的对应的歌曲名称,可以自己美化一些
num = input('请输入您喜欢听的歌曲所对应的序号:')
song_data = session.get(url=f'{self.url}{self.song}&n={num}')
song_url = song_data.json()['url']
song_content = session.get(song_url).content
# 这里我用你搜索的名称做文件名,可以更改
with open(f'./{n}.mp3', mode='ab') as so:
so.write(song_content)
if __name__ == '__main__':
# 要求输入搜索内容
n = input('您想要搜索什么歌或者歌手:')
# 引用上面class ShanHai()类
ShanHai(n)















- 最新
- 最热
只看作者